So for my final, I eventually decided on this goal:
a p5 based template for training RL models on games, with the hope of eventually having a game library in p5 that allows users to easily and intuitively set up custom board games (with boards, pieces, scorekeeping, and more) or select from pre-designed games such as Chess, Go, and other classics that are used as benchmarks for reinforcement learning algorithms. Ideally have trained a model that can play a game against me (and not lose horribly)
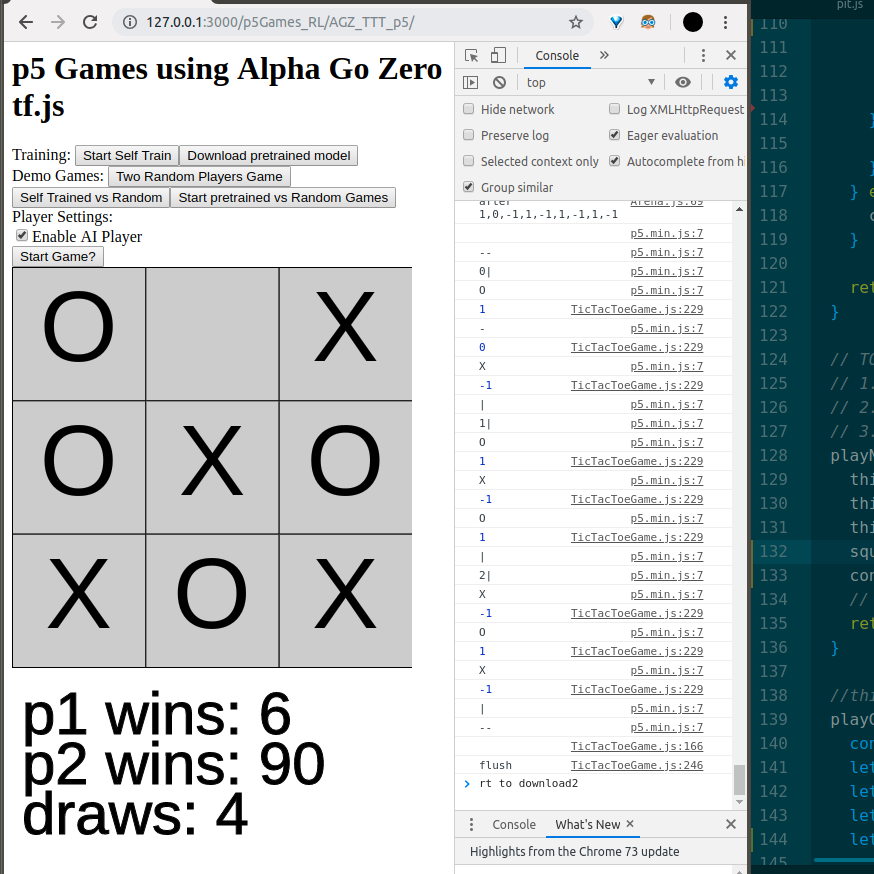
And what I ended up with was a great exploratory foundation to that idea haha. I have a game of tic tac toe in the browser, with a downloadable or self-training model that you can play against. I’m really excited to use this as a jumping off point for more games and more RL. Though a part of me wishes I had expanded upon my fun KNN-Classifier game from Week 2…
When I first started working on this, I was convinced I would have to try and train the model from scratch by doing some sort of adversarial/genetic algorithm based training program that would start with randomly generated neural networks playing games of tic tac toe against each other, and using the victor as the template for a new generation of opponents, gradually increasing in playing strength each time.
Upon researching how other models learn how to play games, I encountered a lot of interesting aspects of reinforcement learning: Deep Q Networks, alpha-beta pruning, minimax search algorithms, and more. All were sort of adjacent to what I was looking for, but it wasn’t until I learned about “Universal Learning Architectures” that I realized what I needed to base my system off of — Alpha Go Zero.
Since Go is considered the most complex of the classic abstract board games, it was a big deal when Google Deep mind’s original model, Alpha Go, beat the world’s best go player, Ke Jie. Alpha Go was trained on thousands of recorded human-played Go games, but the model that eventually surpassed it wasn’t trained on any. When the successor, Alpha Go Zero, was developed, it only took 21 days of training to surpass the original, and instead of learning from pre-played games, it simply played against itself over and over in a similar way to what I was proposing at the beginning of my project. It didn’t know anything about the game other than what the legal moves were and who had won at the end.
Just as a side note, I think this is one of the most revolutionary aspects of this type of Machine Learning, because instead of having to do the most challenging and often controversial part of training, data collection, all the data is self-generated with no need for human input.
So the model that I eventually used was called Alpha Zero General, based on Alpha Go Zero, but using that universal learning architecture aspect that allows it to be thrown at any game and learn how to play with no need for human input. My implementation was based off of the following previous implementations, thanks so much to those who made this possible!
https://github.com/grimmer0125/alphago-zero-tictactoe-js
https://github.com/suragnair/alpha-zero-general/tree/master/connect4
https://arxiv.org/abs/1712.01815
From that paper, this is how they describe their methods:
For at least four decades the strongest computer chess programs have used alpha-beta search (18, 23). AlphaZero uses a markedly different approach that averages over the position evaluations within a subtree, rather than computing the minimax evaluation of that subtree. However, chess programs using traditional MCTS were much weaker than alpha-beta search programs, (4, 24); while alpha-beta programs based on neural networks have previously been unable to compete with faster, handcrafted evaluation functions. AlphaZero evaluates positions using non-linear function approximation based on a deep neural network, rather than the linear function approximation used in typical chess programs. This provides a much more powerful representation, but may also introduce spurious approximation errors. MCTS averages over these approximation errors, which therefore tend to cancel out when evaluating a large subtree. In contrast, alpha-beta search computes an explicit minimax, which propagates the biggest approximation errors to the root of the subtree. Using MCTS may allow AlphaZero to effectively combine its neural network representations with a powerful, domain-independent search.